Document Read Agent
Document Read Agent 使用大型語言模型(LLM)擷取文件中的資訊,並將結果輸出至工作資料夾的文檔。GPT 模型在解析 PDF 檔案中文本資料是採取文本分析,而 Gemini 模型則是將 PDF 檔案中所有資料都視為圖像分析。如果不熟悉如何提示語言模型達成任務目標,可以善用「Ask EMILY」讓 AI 生成友善語言模型的目標提示。
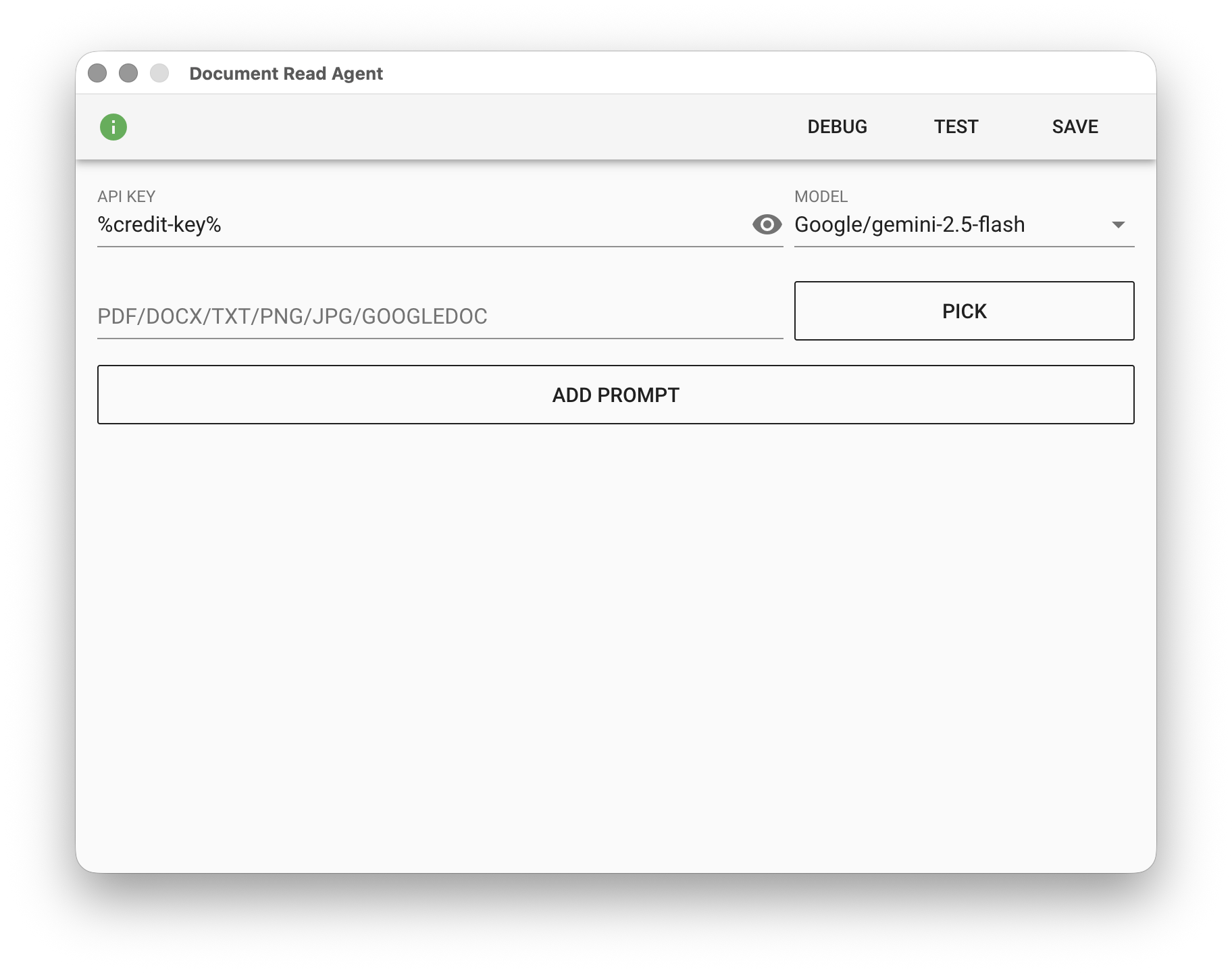
參數
API KEY - OpenAI 或 Google 的 API 金鑰,支援 %FILENAME% 變數,或使用儲值的專用金鑰 %credit-key%。
- OpenAI API Key 請參閱 OpenAI 金鑰申請
- Google API Key 請參閱 Gemini 金鑰申請
MODEL - 目前支援以下模型:
| 平台 | 模型 | 價格 |
|---|---|---|
| OpenAI | gtp-5, gpt-5-mini, gpt-4.1, gpt-4.1-mini | OpenAI 官網 |
| gemini-3-pro, gemini-3-flash, gemini-2.5-pro, gemini-2.5-flash | Gemini 官網 | |
| Anthropic | claude-opus-4-6, claude-sonnet-4-6, claude-haiku-4-5 | Anthropic 官網 |
PDF/DOCX/TXT/PNG/JPG/GOOGLEDOC - 輸入的文件檔。點擊「PICK」選取檔案,或使用 %FILENAME% 變數。除了左列的文件格式檔案外,也支援 Google Docs ID。
ADD PROMPT
加入自然語言提示詞來告訴模型擷取網頁中的資訊。FILENAME 用來指定寫入的工作資料夾檔案。PROMPT 則是提示模型擷取網頁中什麼資訊。
範例
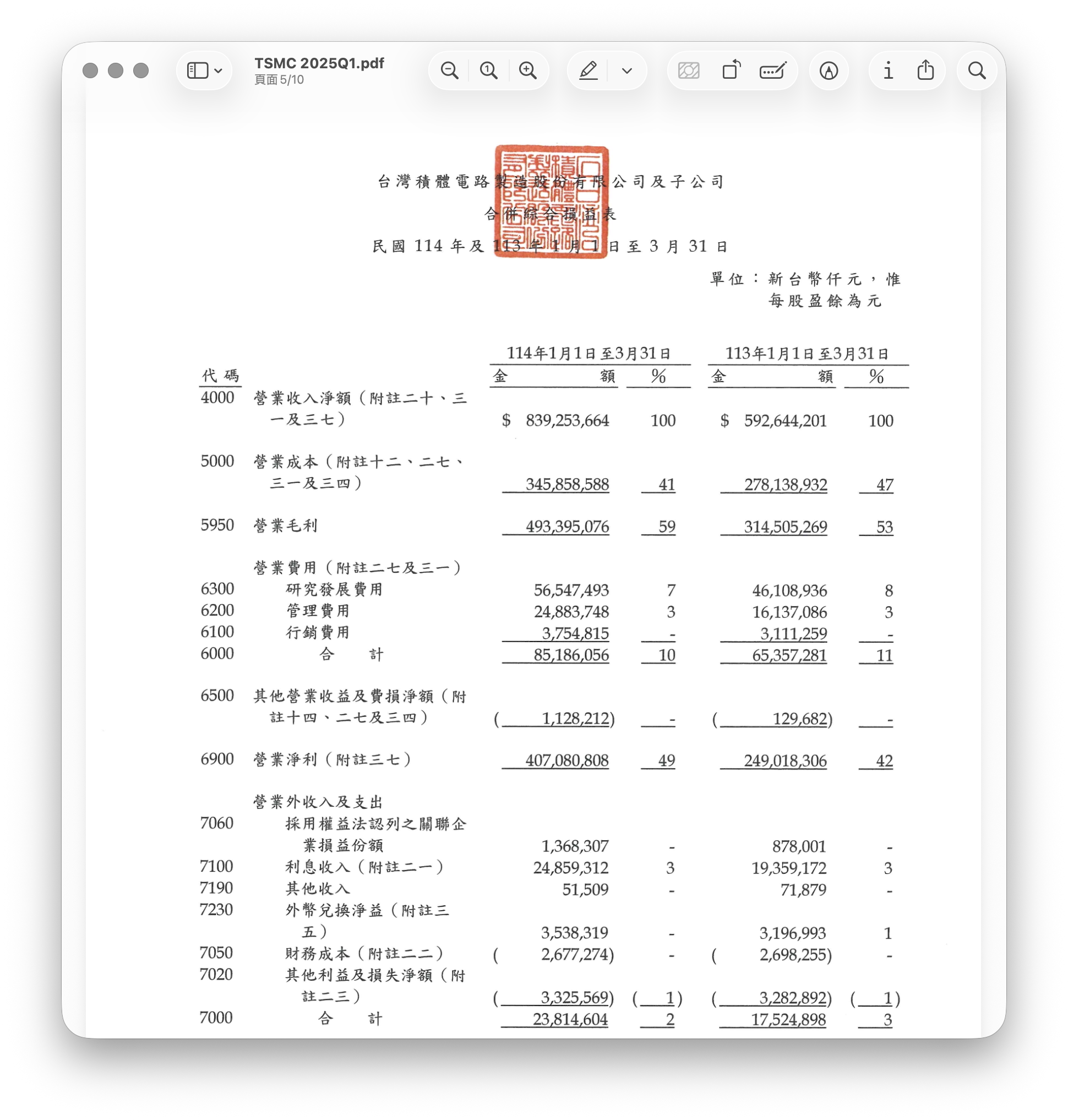
以台積電的財報為例,目標是擷取 114 年第一季的營收。
Document Read Agent 模型選擇 Google/gemini-2.5-flash,加入一個提示,檔名是 revenue,內容是 台積電114年第一季營收。
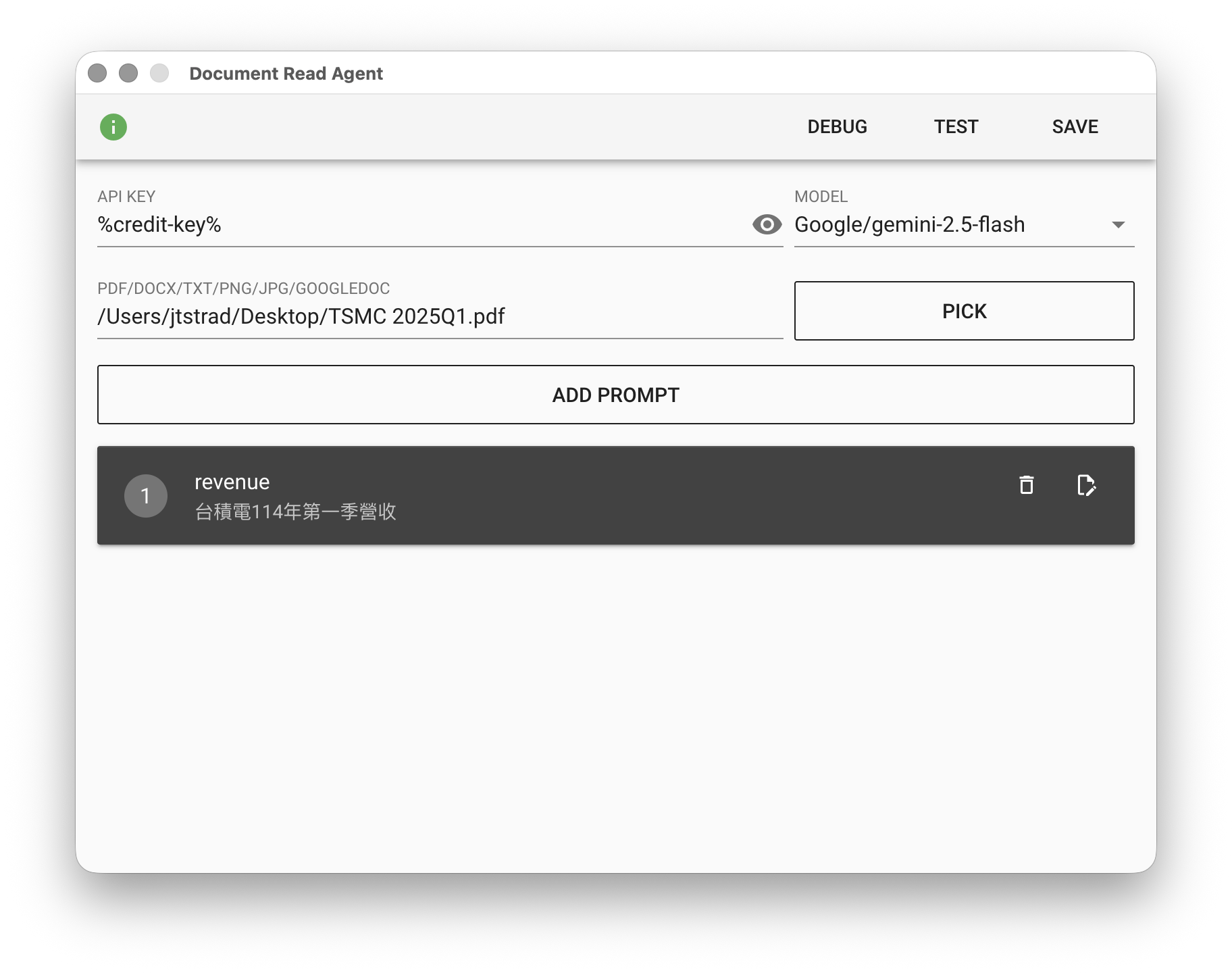
最後點擊「TEST」測試看看,然後檢查工作資料夾中 revenue.txt 內容是否正確。
